M1芯片MacBook搭建本地大模型
文章目录
龙云尧个人博客,转载请注明出处。 CSDN地址:http://blog.csdn.net/michael753951 个人blog地址:http://yaoyl.cn
有了Docker之后,就可以在电脑上干很多事情,就比如搭建一个参数不大的LLM为我们提供服务~~
我已经在github上创建了一个仓库,方便大家使用,如需交流学习,可以clone到本地:https://github.com/YunyaoLong/qwen-coder
安装Ollama
为了能够在本地直接运行大模型,最简单和常见的方式就是使用Ollama。
Ollama支持运行在Docker中,安装的时候需要留意一下自己的内存大小是否满足你所选取的模型需求。
例如我的 16G 内存可以运行 qwen2.5-coder:1.5b-instruct-q5_K_M 和 qwen3:1.7b-q4_K_M,运行更大参数的模型时,会直接提示内存不足,Ollama启动失败。
下面是我的docker-compose.yml文件,可以参考:
1# docker-compose.yml
2services:
3 ollama:
4 image: ollama/ollama:latest
5 ports:
6 - "11434:11434" # 端口映射
7 volumes:
8 - ./models:/root/.ollama/models # 指定Ollama的卷目录,这样就不需要频繁拉取LLM的二进制文件了
9 environment:
10 - OLLAMA_HOST=0.0.0.0
11 - OLLAMA_MAX_LOADED_MODELS=1 # 只加载一个模型,防止内存占用过多导致Ollama启动失败
12 - OLLAMA_KEEP_ALIVE=5m # 模型常驻内存,避免反复加载
13 deploy:
14 resources:
15 limits:
16 memory: 12G # 显式限制,防止超用
17 restart: unless-stopped
18 # 设置 entrypoint 为 shell,并传入命令
19 entrypoint: ["/bin/sh", "-c"]
20 command: |
21 "
22 # 启动 Ollama 服务(后台)
23 ollama serve &
24
25 # 等待服务启动
26 sleep 5
27
28 # 拉取模型
29 echo '📥 开始下载 qwen:7b-chat-q4_K_M...'
30 ollama pull qwen:7b-chat-q4_K_M || echo '⚠️ 下载失败'
31
32 echo '📥 开始下载 qwen3:4b-instruct-2507-q4_K_M...'
33 ollama pull qwen3:4b-instruct-2507-q4_K_M || echo '⚠️ 下载失败'
34
35 echo '📥 开始下载 qwen3:4b-instruct...'
36 ollama pull qwen3:4b-instruct || echo '⚠️ 下载失败'
37
38 echo '📥 开始下载 qwen2.5-coder:3b...'
39 ollama pull qwen2.5-coder:3b || echo '⚠️ 下载失败'
40
41 echo '📥 开始下载 qwen3:1.7b-fp16...'
42 ollama pull qwen3:1.7b-fp16 || echo '⚠️ 下载失败'
43
44 echo '📥 开始下载 qwen3:1.7b-q4_K_M...'
45 ollama pull qwen3:1.7b-q4_K_M || echo '⚠️ 下载失败'
46
47 echo '📥 开始下载 qwen2.5-coder:1.5b-instruct-q5_K_M...'
48 ollama pull qwen2.5-coder:1.5b-instruct-q5_K_M || echo '⚠️ 下载失败'
49
50 echo '✅ 所有模型下载完成!服务持续运行中...'
51
52 # 保持容器不退出(等待 Ollama serve)
53 wait
54 "
启动方式1
接着在 docker-compose.yml 所在的工作目录启动:
docker-compose up -d
启动方式2
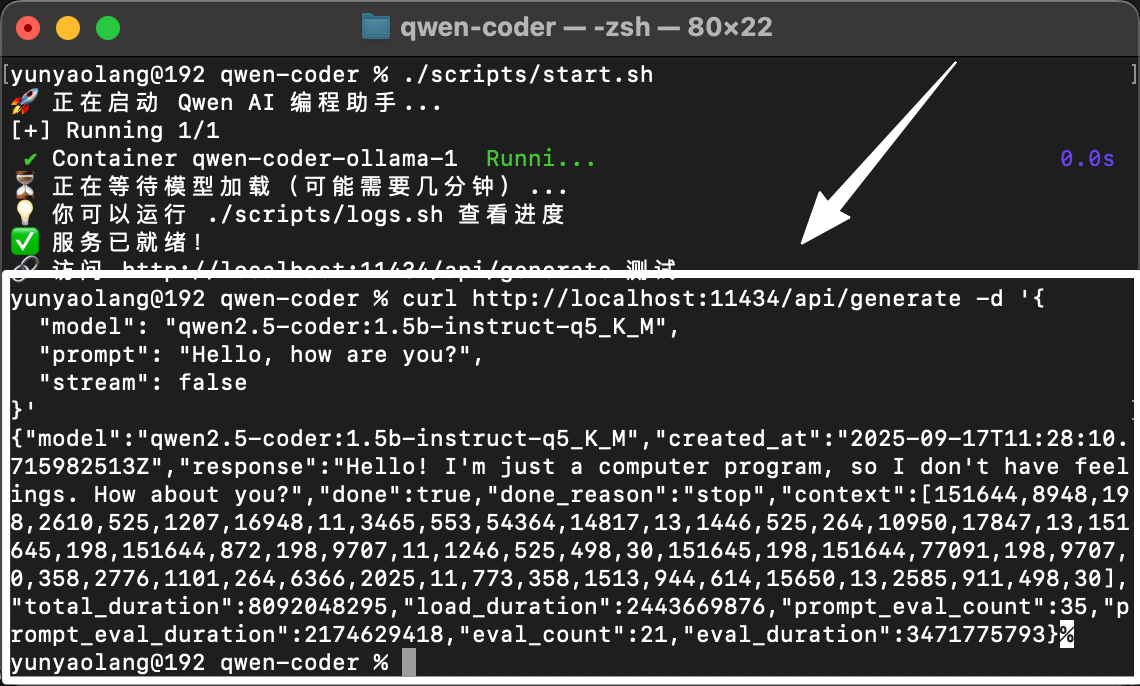
或者也可以直接调用我的 start.sh 脚本(for CI/CD)
运行检查
查看模型列表
查看方式1:通过命令行直接查看
docker-compose exec ollama ollama list
这行命令可以查看运行中的 Ollama 中,所有已下载的模型。(列表中的模型不一定真的被加载)
查看方式2:通过Ollama服务API接口查看
或者通过Ollama服务的API接口进行查询:
curl http://localhost:11434/api/tags
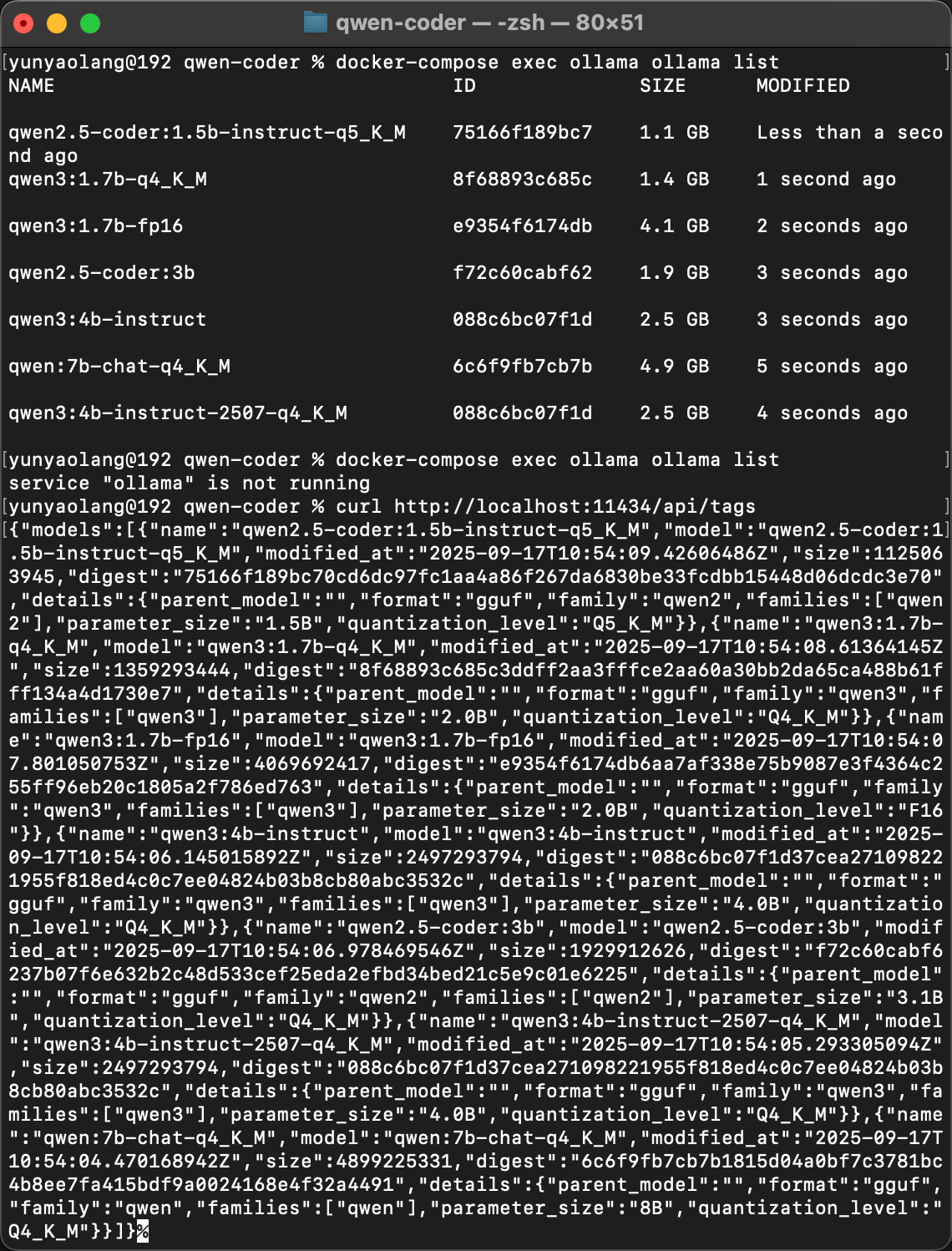
这里说一个背景知识:Ollama在运行过程中,是不会默认加载模型,需要调用模型时才会加载。所以我们不用担心下载了很多个模型之后,内存占用是否足够的问题。
测试模型
调用方式1:基于Rest接口访问大模型
尝试访问Ollama服务的rest接口。
1curl http://localhost:11434/api/generate -d '{
2 "model": "qwen2.5-coder:1.5b-instruct-q5_K_M",
3 "prompt": "Hello, how are you?",
4 "stream": false
5}'
通过Rest接口访问大模型时,是无状态的,每次调用都会生成新的结果。
调用方式2:基于shell命令调用大模型
例如我想直接在命令行中访问我已经下载好的 qwen3:4b-instruct 模型。
docker-compose exec ollama ollama run qwen3:4b-instruct

通过命令行访问大模型时,Ollama帮我们管理了会话信息,因此支持连续对话。
日志查看方式1:直接从Docker-desktop中查看
如果Ollama成功加载模型,你可以在Docker容器中查看输出结果:
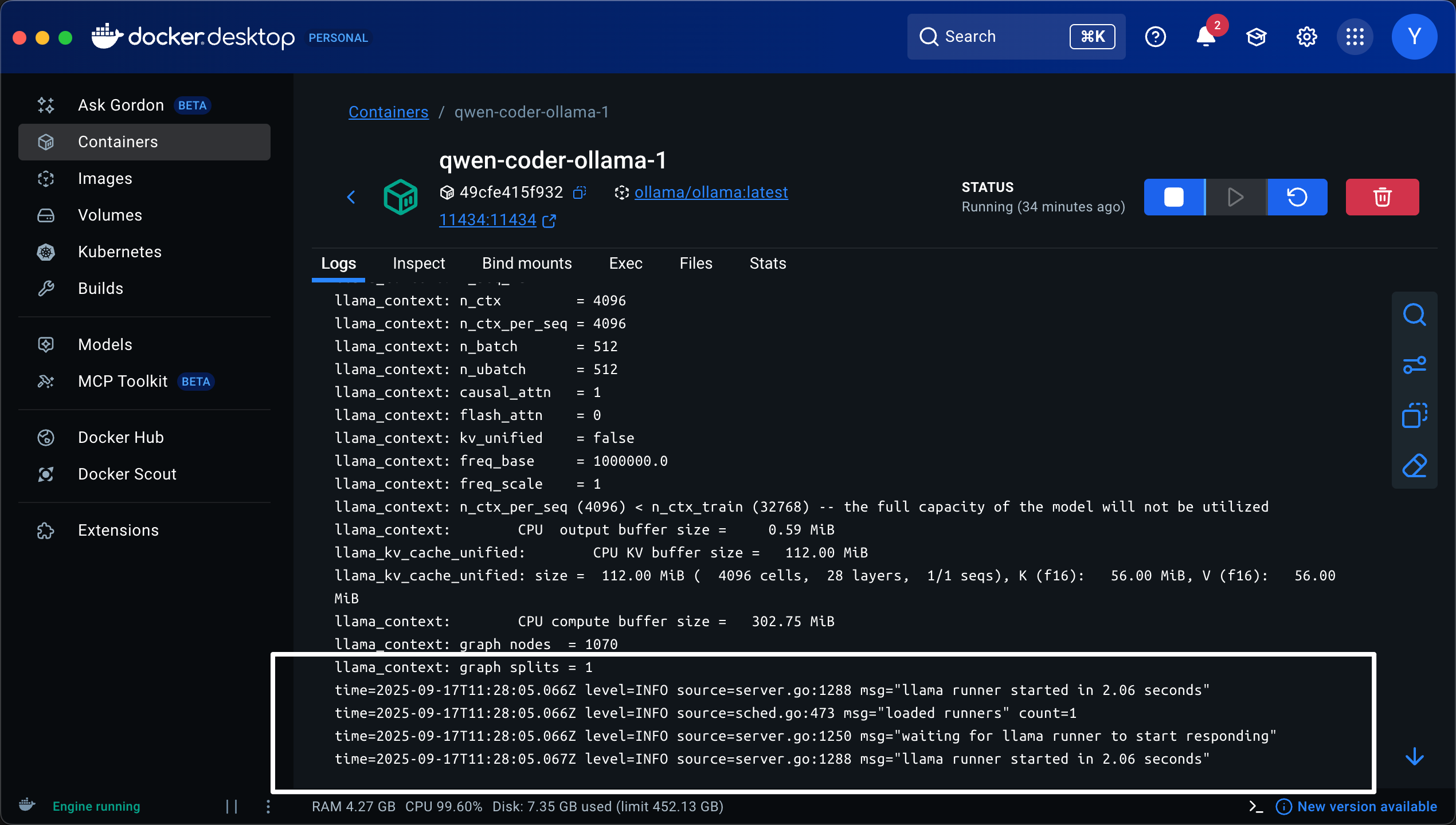
日志查看方式2:通过命令行查看
或者通过如下命令行查看日志也能看到上图日志的输出:
docker-compose logs ollama
同时在间隔一段时间之后,你会在控制台中看到响应结果:
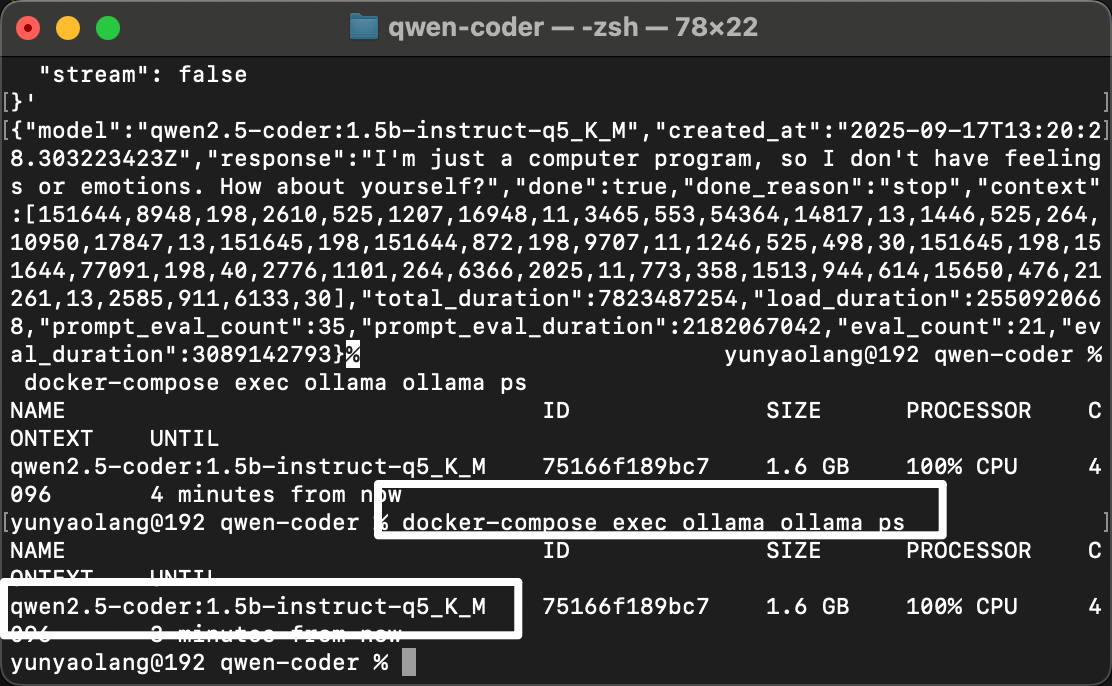
以及,此时如果你执行ps命令,你就能够看到 qwen2.5-coder:1.5b-instruct-q5_K_M 已经被加载了:
docker-compose exec ollama ollama ps
Ollama 背景知识
Ollama 加载大模型的机制
模型拉取与存储
当执行 Ollama pull 命令时,模型会被下载并存储在本地(例如我的配置中定义的位置是 ./models:/root/.ollama/models)
这些模型文件会持久化保存在磁盘上;
模型加载机制
- Ollama 默认不会在启动时自动加载所有已下载的模型到内存;
- 模型通常是在首次被调用(如 Ollama run 或 API 请求)时才加载到内存;
- 如果我在配置中设置了 OLLAMA_KEEP_ALIVE=5m,意味着模型在5分钟无活动后会从内存中卸载;
- 我在配置中定义了 OLLAMA_MAX_LOADED_MODELS=1,意味着统一时间只会有一个模型被加载到内存中;
运行模型
如前文所说,通过 curl http://localhost:11434/api/tags 看到所有模型的问题:
- 这个 API 只是列出所有已下载的模型,而不是已加载的模型;
- 列出模型标签并不意味着它们都被加载到内存中;
- 实际的内存消耗发生在模型真正被加载时(首次使用时);
注意,Ollama不只能够运行本地大模型,还支持通过 指定host + apiKey 运行远程模型,比如 OpenAI 的模型。
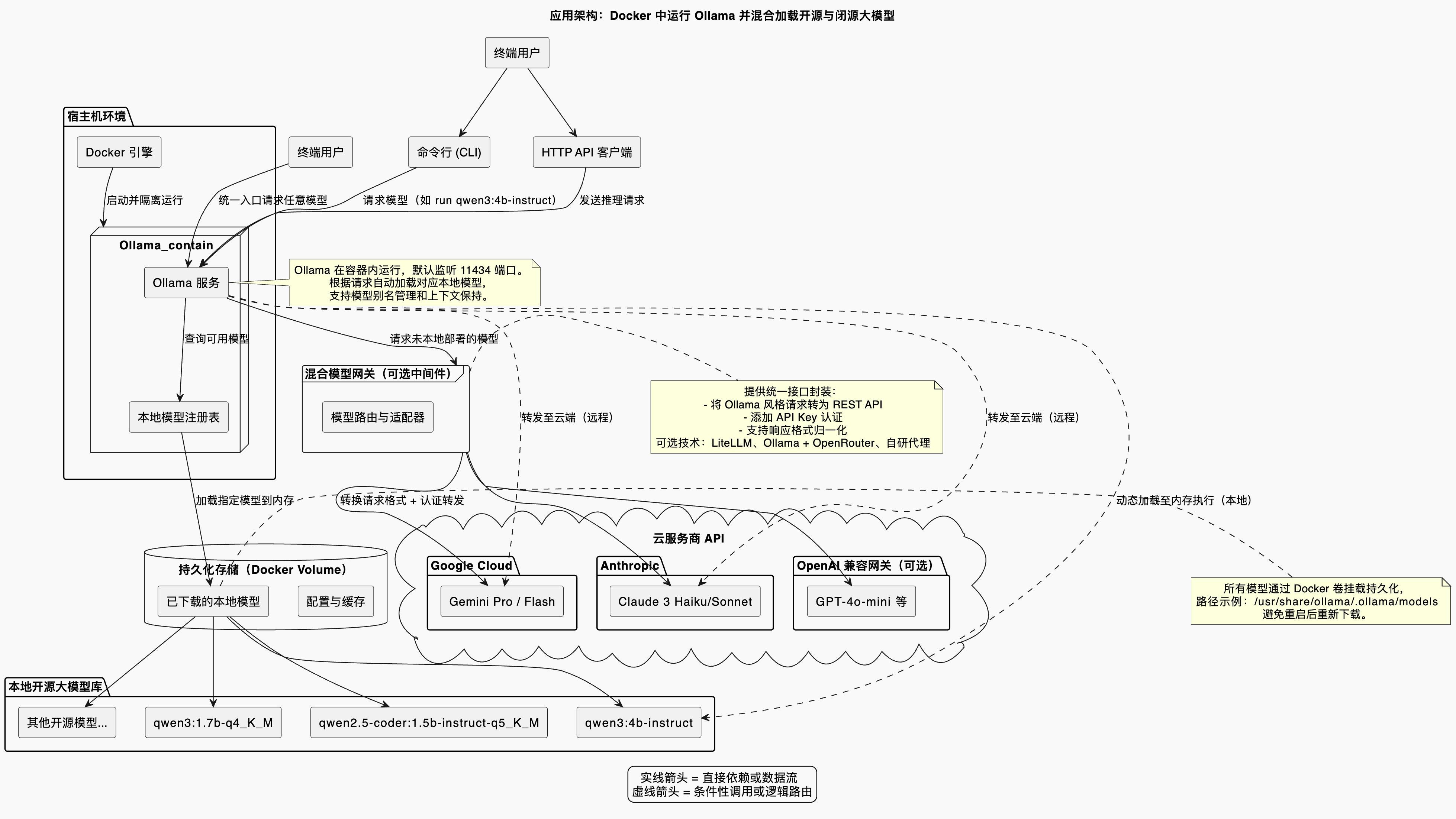
一个简单的Ollama混合加载大模型的架构示意图如下: