在VSCode中使用Continue插件连接本地大模型
文章目录
龙云尧个人博客,转载请注明出处。 CSDN地址:http://blog.csdn.net/michael753951 个人blog地址:http://yaoyl.cn
在前面的章节中,我们已经成功地在M1芯片的MacBook上安装了Docker,并且在本地成功运行起来了属于自己的大模型服务(Ollama)。
现在,我们来正式好好开发一下我们的LLM。本次我们将在VSCode中使用Continue插件连接本地运行的Ollama服务,看看业界比较成熟的智能体(Agent)是如何使用LLM解决各种问题的。
Continue插件简介
首先我们看看Continue是什么。
它是一个VSCode插件,允许开发者在IDE中直接使用AI大模型进行代码编写、调试和重构。
与传统的在线AI服务不同,Continue支持配置使用本地运行的模型服务,这样我们可以:
- 三方LLM供应商的收费API,免费查看LLM的执行结果;
- 实时查看LLM的日志,观察LLM如何运行;
- 对Ollama服务直接抓包,没有SSL加密,可以非常清晰的看到请求和响应;
- Continue插件需要连接到大模型服务才能发挥作用,因此请确保Ollama服务正在运行;
- 本地大模型的性能受硬件资源限制,复杂请求可能需要较长时间处理;
- Continue插件会缓存对话历史,长时间使用可能占用较多内存;
安装Continue插件
首先,在VSCode的扩展市场中搜索"Continue"插件并安装。
安装完成后,重启VSCode以确保插件正常加载。
配置Continue连接本地Ollama
Continue插件的配置文件通常位于 ~/.continue/config.yaml。
或者可以直接在Continue插件中,通过CONTINUE ⚙ -> Configs -> Local Config ⚙也能直接打开config.yaml。
由于新插件刚开始使用yaml进行配置,因此网上相关的教程并不多。建议直接查看官网的配置教程,这里我参考的是基于运行了qwen2.5-coder的Ollama服务的Continue配置。
配置文件详解
1name: Local Agent
2version: 1.0.0
3schema: v1
4models:
5 - name: qwen2.5-1.5b-instruct
6 provider: ollama
7 model: qwen2.5-coder:1.5b-instruct-q5_K_M
8 apiBase: http://localhost:11434
9 roles:
10 - apply
11 - autocomplete
12 - chat
13 - edit
14 temperature: 0.2 # coder LLM用于代码补全等功能时,建议降低一点自由度
15 topP: 0.9
16 - name: qwen3_1.7b-q4
17 provider: ollama
18 model: qwen3:1.7b-q4_K_M
19 apiBase: http://localhost:11434
20 temperature: 0.7
21 topP: 0.9
22 - name: qwen3:0.6b
23 provider: ollama
24 model: qwen3:0.6b
25 apiBase: http://localhost:11434
26 temperature: 0.7
27 topP: 0.9
28tabAutocompleteModel: qwen2.5-1.5b-instruct
29autocomplete:
30 prefixLines: 20
31 suffixLines: 5
32 debounceTime: 150
33 timeout: 6000
34 maxContextTokens: 2048
让我们详细解释一下配置文件中各个参数的含义:
模型配置参数
name: 模型在Continue中的标识名,便于区分不同模型;provider: 模型提供商,这里设置为ollama表示使用本地Ollama服务;model: Ollama中实际的模型名称,需要与Ollama中的模型名保持一致;apiBase: Ollama服务的API地址,通常为http://localhost:11434;roles: 模型在Continue中的角色,包括:apply: 用于应用更改autocomplete: 用于代码自动补全chat: 用于对话edit: 用于代码编辑
temperature: 控制模型输出的随机性,值越低越确定性越强;topP: 控制采样范围,值越小越保守;
自动补全配置参数
tabAutocompleteModel: 指定用于Tab补全的模型;prefixLines: 自动补全时考虑的前置代码行数;suffixLines: 自动补全时考虑的后置代码行数;debounceTime: 自动补全的延迟时间(毫秒);timeout: 自动补全的超时时间(毫秒);maxContextTokens: 最大上下文token数;
确认Ollama服务运行状态
在配置Continue之前,你需要先检查Ollama服务的运行状态:
docker-compose ps
确认Ollama容器处于运行状态,端口11434已正确映射。
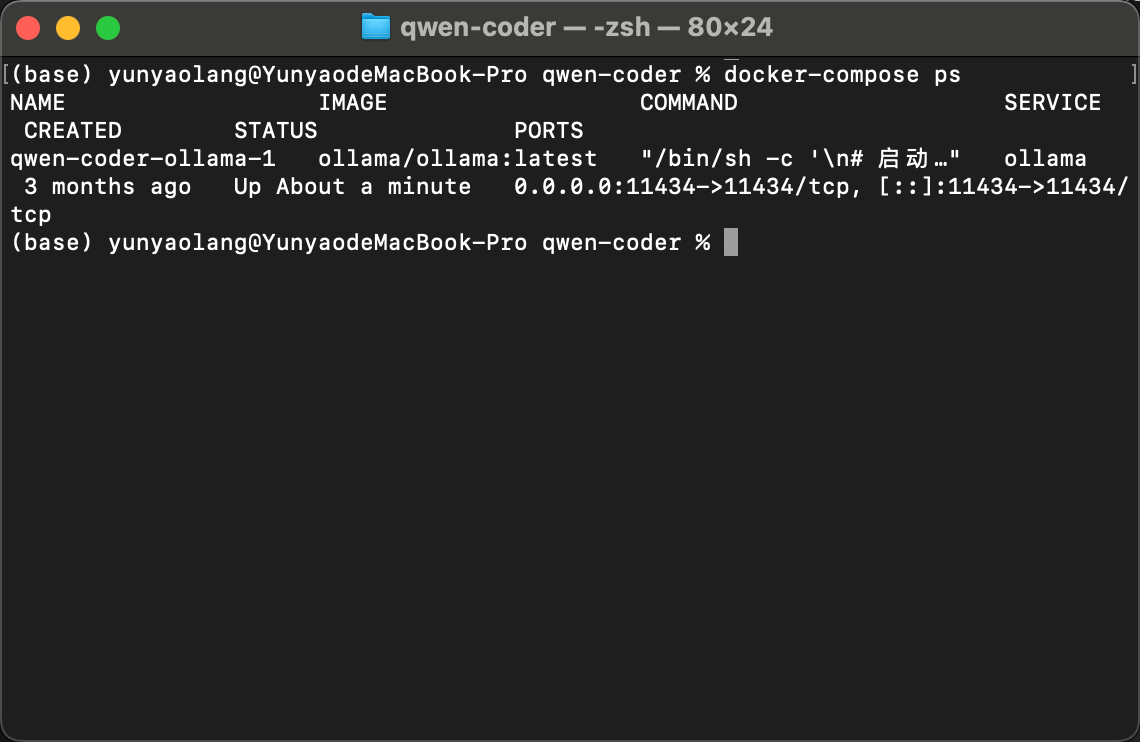
或者直接去Docker-desktop查看Ollama容器的运行状态。
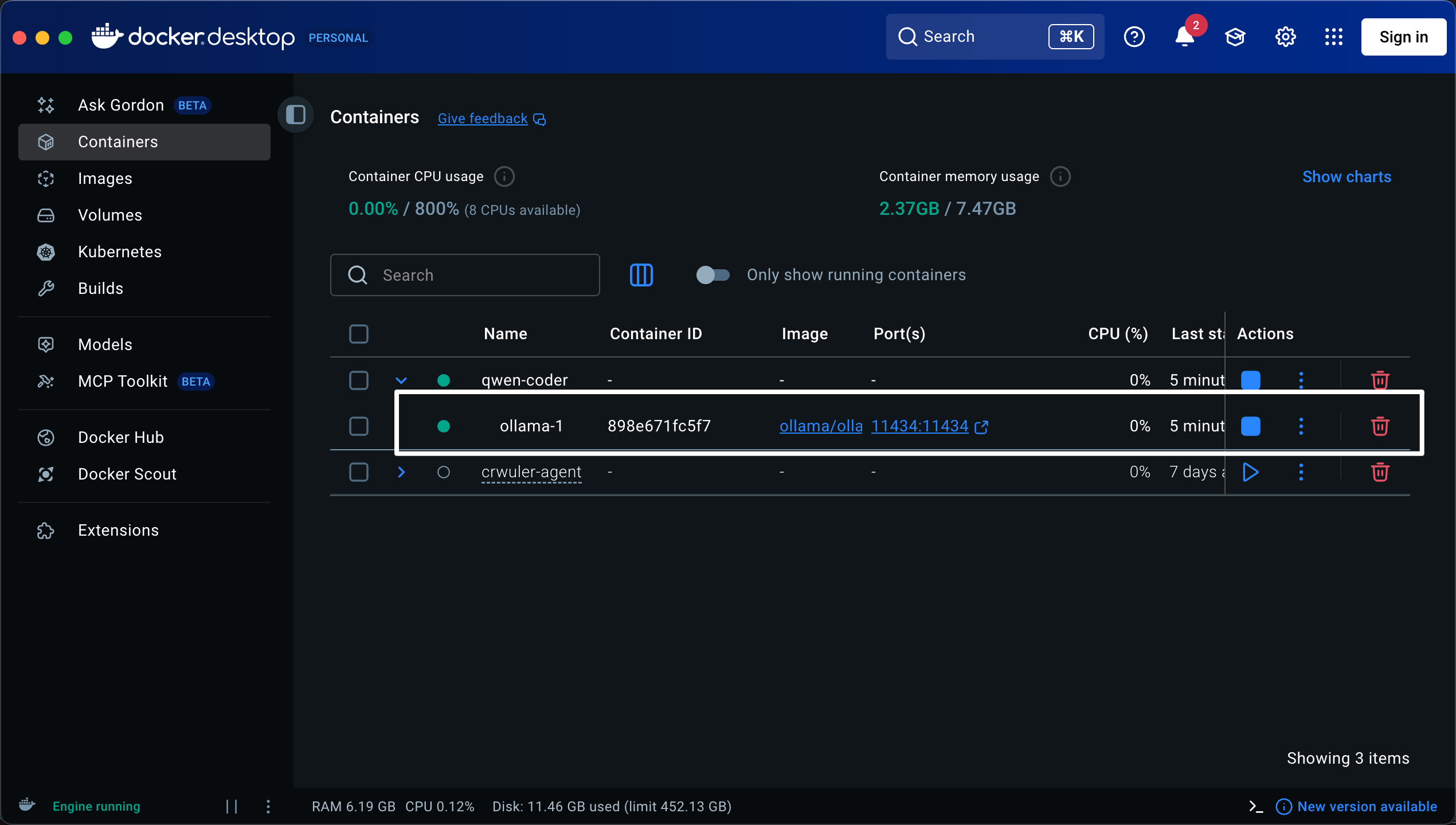
重启Continue插件
配置完成后,重启VSCode或在Continue插件中选择重新加载配置。
使用Continue进行开发
启动Continue会话
在VSCode中,启动Continue会话的方式如下:
- 使用快捷键
Ctrl+L(Windows/Linux) 或Cmd+L(Mac) - 或者在命令面板中搜索"Continue"并选择相应命令
- 在VSCode侧边栏中配置Continue插件(最常用)
基本功能演示
多轮对话
和市面上常见的LLM Agent一样,Continue插件默认支持多轮对话。
ps: 我们在上一章其实发现LLM仅支持一次输入一次输出,而Agent一般都实现多轮对话,后续我们会深挖这其中的原理。
代码自动补全
安装配置好config.yaml之后,你的Continue插件就可以开始给你做代码补全了。
此时当你在VSCode中编写代码时,Continue会根据上下文自动提供补全建议。
Continue的代码补全或者其他的LLM Agent代码补全工具冲突,我们这里想要研究Continue插件,因此建议暂时关闭其他插件的代码补全功能。
代码解释
选中一段代码,然后在Continue输入框中输入"请解释这段代码",Continue会调用本地大模型进行详细的代码解释。
代码重构
如果你需要重构一段代码,可以在Continue中描述你的需求,例如"将这个函数改为异步函数",Continue会根据你的要求提供重构建议。
因为我们运行的是一些小模型,且本地机器性能有限,因此使用Continue调用本地LLM重构时,只能对一些函数进行重构,比如函数内部调用的函数,或者函数内部调用的库函数。
如果涉及到模块级别重构,请使用各个大模型厂商的商用LLM API,保证自己的重构代码质量和响应速度。
错误修复
当代码出现错误时,可以将错误信息和相关代码发送给Continue,让尝试找出问题并提供修复方案。
性能优化建议
模型选择策略
根据不同的使用场景选择合适的模型:
- 对于代码自动补全:使用参数较小、响应较快的模型(如qwen2.5-coder:1.5b-instruct-q5_K_M)
- 对于复杂问题解答:使用参数较大、能力更强的模型(如qwen3:4b-instruct)
内存管理
由于Continue会缓存对话历史,长时间使用可能导致内存占用过高。建议:
- 定期清理Continue的对话历史
- 在config.yaml中适当限制上下文长度
- 监控系统内存使用情况
网络和本地模型切换
Continue支持同时配置多个模型提供商,你可以在本地模型和在线模型之间灵活切换,以平衡性能和成本。
常见问题排查
模型加载失败
如果Continue无法连接到Ollama,请检查:
- Ollama服务是否正在运行
- 端口11434是否正确映射
- 模型名称是否与Ollama中的一致
- 网络连接是否正常
响应缓慢
如果本地模型响应缓慢,可能的原因包括:
- 模型参数过大,超出硬件能力
- 同时加载了多个模型
- 系统内存不足
配置不生效
如果修改了config.yaml但没有生效,尝试:
- 重启VSCode
- 在Continue插件中手动重新加载配置
- 检查YAML格式是否正确
结语
至此,我们已经完成了在VSCode中使用Continue插件连接本地Ollama大模型的完整配置。
后续我们就可以深挖一下Continue插件是如何运行的,从中学习一下Agent的核心思想和实现方式。